Google's Gmail service had yet another widespread outage on Tuesday at 12:30 PM which lasted
more than 3 hours between 100 minutes (according to Google) to 2 ½ hours (according to
PC World). News of the outage quickly spread like a wildfire on social media networks, where it quickly earned the epitaph of Gfail. A great day for Twitter and Facebook! Even by Google's own account, it was a "big deal".
Google's Ben Treynor, VP Engineering and Site Reliability Czar, apologized for the outage in a blog post on the Gmail blog, and explained the technical details of what caused it. I like his
well-crafted response for most part, and although he calls it as it is ("Gmail's web interface had a widespread outage..."), when your web interface is the primary or only interface used by most customers to access your service, for customers the service is down.
With each outage, I've reminded myself that in spite of the best efforts of system and service architects to build as much high availability and quick recovery mechanisms in place, outages do occur— just as they do in your on-premise systems and services, and that there's nothing to be alarmed about unless it forms a pattern.
The latest outage, and the reported reason for it— a
capacity miscalculation according to News.com's Tom Krazit, makes me a little uncomfortable. I use Gmail (there, I said it... just as I use Hotmail/Live, Yahoo!, several flavors of Exchange Server, and other POP/IMAP-based messaging systems), but using it as the primary email system for business, even for free, would be a difficult decision.
As organizations consider the move to the cloud, high availability is one of the many factors that must be carefully considered, and the potential of widespread loss of productivity must be factored in when calculating the cost savings. Additionally, if you rely on a cloud-based e-mail service, an outage like this also brings to a standstill the frantic e-mail and collaboration activity that goes on inside an organization that's dependent on e-mail. What adds to further loss of productivity is the fact that most users using a web-based e-mail service do not have a local copy of their data. Gmail, and other web-based e-mail providers do provide access to e-mail accounts using POP/IMAP e-mail clients, which allows you to download messages to your computer. But when was the last time you used a POP/IMAP client to access your web-based e-mail service?
To make the situation worse, if you depend on the same cloud-based service for your productivity apps such as word processing, spreadsheets, etc., you may as well have taken the day (or at least the few hours) off. Nik Curilovic reports in
Gmail Now Really Down - Can I Get My Email Back Please (Update: Its Back) on TechCrunch.com:
I use Apps For Domain for everything - my contacts, my email, my todo list, my chat, my documents and more recently, my phone. As soon as it went down, I noticed in less than a second. I am now completely stuck, after a few months of being impressed by how I was able to run my entire life on Google.
Gmail is covered by the Google Apps
SLA, which promises an uptime of 99.9%. Going by the proverbial "Nines of High Availability" calculation you've no doubt heard many times over in high availability presentations,
three nines (or 99.9% up time) allows approximately 8.76 hours of unplanned down-time in a year. Yesterday's outage consumed more than one third of that.
Gmail's Site Reliability Manager, Acacio Cruz, says in a
Current Gmail Outage post on the official Google blog:
Obviously we’re never happy when outages occur, but we would like to stress that this is an unusual occurrence.
PC World's JR Raphael notes:
While "frequent" would probably be an exaggeration when it comes to describing Gmail outages, "unusual" might be missing the mark by a hair, too.
Raphael chronicles Gmail outages in
Gmail Outage Marks Sixth Downtime in Eight Months.
The total downtime, as stated by Raphael in the above article, is approximately 71 hours or more! The three longest outages lasted 30 hours, 24 hours, and 15 hours respectively. Yesterday's outage was world-wide.
To Gmail's defense, with the highly distributed nature of web-based services that have a global reach and are likely spread over many data centers in different parts of the world, a single user wouldn't have been affected by all outages. But it's an alarming number nevertheless. If you were affected by all the outages, it would translate to less than 99% availability
(99.97% availability allows you little over one day of downtime), a figure most organizations wouldn't be comfortable with. On the flip side, Google would've rewarded you with 7 days of free service, "at no charge to customer" according to the
Google Apps SLA— if you notify Google within 30 days from the time you become eligible for the credit.
If your organization require a higher SLA for its messaging system, and you've deployed high availability configurations to achieve higher uptime, this cloud clearly isn't for you.
How does Gmail's SLA and uptime stack up against your organization's internal SLA for e-mail? Will your users be satisfied with Gmail's report card?
Labels: Clustering, Newsbytes

 Exchangepedia Blog is read by visitors from all 50 US States and 150 countries world-wide
Exchangepedia Blog is read by visitors from all 50 US States and 150 countries world-wide Permalink
Permalink
 1 Comments Post a comment
1 Comments Post a comment
 links to this post
links to this post
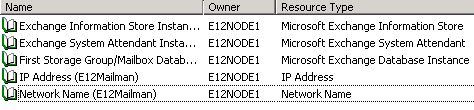
 Demo:
Demo: 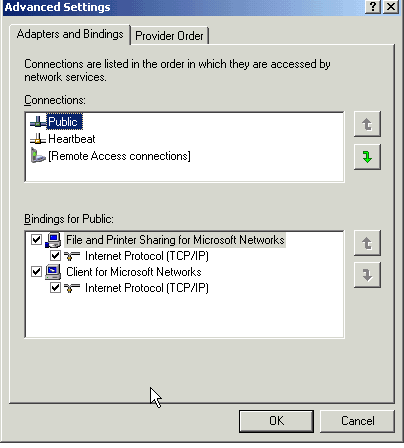



{kind=link}